Author: Brad Corrion IOTech Chief Technology Officer
First published on October 18th, 2024 on Brad Corrion's LinkedIn profile
Synergy for Energy Event in Houston | IOTech & Acuvate
Recently I had the chance to present at Acuvate's Synergy For Energy event in Houston as IOTech Systems software represents “Edge Computing”, one of the key links in Acuvate’s technology platform supporting the Energy industry.
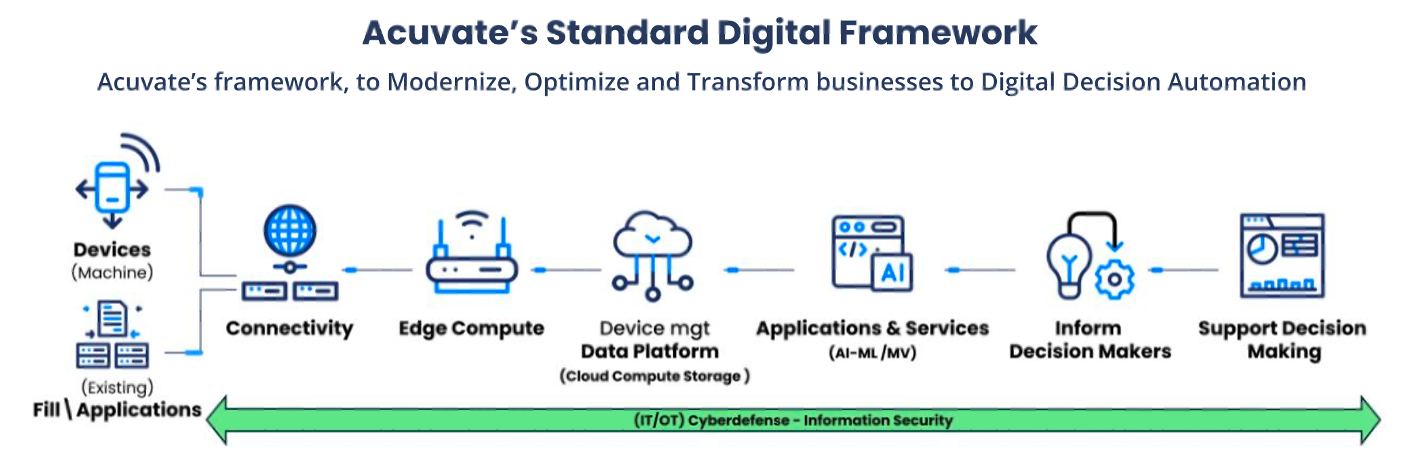
The Acuvate Standard Digital Framework, a way to design systems that span The Edge to the Cloud
Initially, I was a bit stymied on how to participate in an event with a 25-minute time budget: do I assume the audience is inherently familiar with edge computing, or is it the first time they have heard of the phrase? Not that 25 minutes allows for a great treatise on any topic but the decision is impactful. Ultimately, I chose to assume that Edge Computing is a new term, but tailored my presentation toward Energy examples where possible.
What is Edge Computing?
It had been a long time since I spoke to a message like this - akin to asking an astronaut to define “space” — it should be easy to do, but after spending the last decade of my career deep in the weeds it was refreshingly challenging. What compounds this further is that embedded computing is a known space, having laid historical foundations with layers and layers of practical solutions that have served our needs for decades.
I settled on what I think is the most applicable definition for any audience: “Edge computing is the placement of compute infrastructure as close to the source of data as makes sense”. Let’s break those weasel words down:
- “Compute Infrastructure”: the systems that have something to do: collect data, manipulate data, analyze data, or move data to another destination. It could be a huge x86 server or a tiny ARM-based gateway.
- “The source of data”: Your data is originating somewhere as it winks into existence: a sensor on a production line, an electrical current reading in a battery cell, a people counter in a retail environment, and so on. Some of this data is already well plumbed, but some may not be currently accessible. It may be locked behind a vendor’s walled garden, or it may be present but uncollected because the tech never configured it during the initial installation. But through the aggregation of this data you can figure out a geographic center that roughly corresponds to where the data is coming from: a production line, a factory, a store, a building, and so on.
- “As close … as makes sense”: This turn of phrase allows everyone in the audience to adopt edge computing yet having something unique to their needs. Unlike Cloud Computing, where you pretty much choose between 3-5 suppliers, or on-premises computing where it’s clearly installed on-site somewhere, the phrase “as close as makes sense” means that Edge Computing could be anywhere along that spectrum, including various telco facilities, co-location centers, datacenters and so on.
“As makes sense” is a catch-all for the math that needs to be done to decide on the cost and performance trade-offs:
- Is the volume of data so great that moving it to the cloud is too costly?
- Is the latency, the length of time it takes to move the data somewhere, too slow that it justifies putting the analysis of the data closer to its source?
- Is the cost of ownership to put the workload in a co-location facility cheaper than the cost on-premises plus the cost of carriage?
These are but some of the questions that will help to formulate where your Edge will be located
But in the end, if your compute isn’t located in the cloud, then Edge Computing probably means that the infrastructure is way over there, which creates problems for our evolving IT and OT teams.
The Challenges of the Edge
So now that we have re-established what the Edge is, it wouldn’t be interesting unless it was challenging. And we have at least three reasons why it is challenging.
- First off, the Edge is challenging simply because it is way over there, which means from a vendor’s perspective, every deployment is unique in both physical location network security and administrative access. This makes it expensive to send technicians or gain access to any remote system, whether on an oil derrick, a utility pole, or deep inside a factory.
- But it is challenging for a timelier reason: The Edge is at the nexus of old and new computing. With IT infrastructures being turned upside down to move them to the cloud, first virtualizing then containerizing huge arrays of formerly on-premises, physical compute, the amount of energy and investment being put into software tooling is hugely compelling to adopt for the edge. The competition for talent is real, and if this new thing called the edge uses old and stodgy technologies, then only old and stodgy employees will want to work on it. But on the other hand, the Edge is completely opposite of the scale that makes the cloud possible. Instead of a virtual array of thousands of servers, all identical, all easily addressable by software tools, we have thousands of different devices flung around the world. This puts a serious crimp on the cloud tools when we try to apply them to workflows at the Edge.
- And finally, at the Edge every device is a snowflake. Even when an edge server is identical across all the factory deployments, and even if accessibility and connectivity is consistent, I will be dollars to donuts that the contents, configuration and utilization of each server is unique from all the rest. So, in the cloud, if a VM dies, you nuke it and fire up a replacement. At the edge, if a server dies, you need to remediate the hardware, and then restore the operating state and configurations of all the highly valued, and highly unique edge applications. And the very nature of this vast collection of snowflakes is that mining the edge’s connected devices is a labor of grand proportions, having to navigate vendor walled gardens, a sea of device protocols, and the accounts, passwords and metadata (such as tag labels) required to properly access and utilize the data.
The Solution: Open Source, Platforms and IOTech
Fortunately many people have been motivated to address that list of challenges. The first solution I covered was introducing EdgeX Foundry, the open source project hosted under the The Linux Foundation's LF Edge umbrella. EdgeX (for short) was founded in 2017 to address the challenges of edge and IOT integrations using architectures and technologies inspired by the cloud computing revolution. It uses a pretty typical northbound / southbound fanout sandwiching an event bus for sharing data. The southbound side represents a broad suite of popular industrial and IOT protocols for connecting with the data-producing devices, and the northbound represents the connectors and transforms that connect collected data to the cloud or other destinations. The data bus in the middle plays an oft-overlooked purpose, however, by requiring that all data coming from southbound devices be normalized into a consistent format, using consistent metadata to describe the contents of the messages. Combined with an abstracted command API, North-side consumers can access data and control devices with consistent APIs and consistent formats, which creates great integration efficiencies for teams.
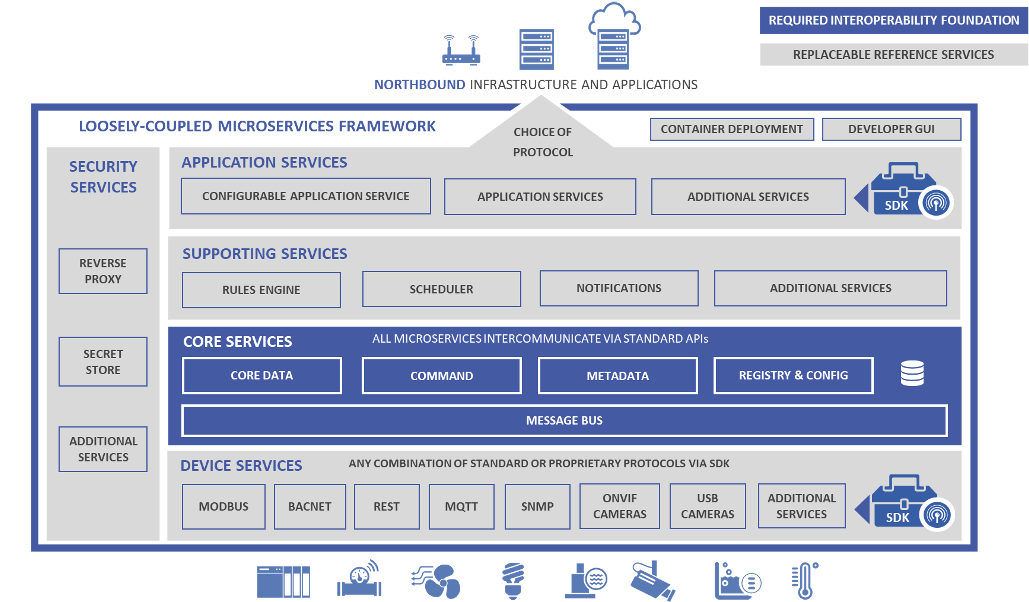
The EdgeX Foundry Basic Architecture
By being open source, the community shares the burden of keeping the boring stuff functional (yet innovative) and keeping the APIs consistent, while adopters can focus on the value-added goodness that they integrate and bring to market.
At IOTech Systems we have witnessed three common adoption motivations for EdgeX:
- Normalizing the platform and infrastructure for all of the teams internal to a large organization
- Normalizing the vehicle to deploy multiple services on-premise in customer environments
- Normalizing the infrastructure for competitors and collaborators to interoperate across industry verticals
The common thread in all of the above patterns is that currently too many teams are inefficiently investing in too many of the same, boring infrastructures, and that the collective organization could move faster if they agreed on a platform like EdgeX.
From there I introduced Edge Central, which is IOTech’s curated commercial offering built around EdgeX. While it does pass through the core EdgeX services, we also bundle additional value-add around the platform, such as OPCUA servers and browsers, Sparkplug B servers, User Interfaces and so on. Further it’s important to know that any EdgeX compatible services will work with Edge Central, and any of our Edge Central investments will work with EdgeX. This allows us to tailor to whatever needs our customers have with EdgeX, from a total platform to a-la-carte piece adoptions. The full stack of IOTech software starts at the bottom with a focus on high performance, embedded connectivity software (Edge Connect), our integrated EdgeX offering (Edge Central), and a suite to manage hundreds and thousands of edge software deployments (Edge Manager).
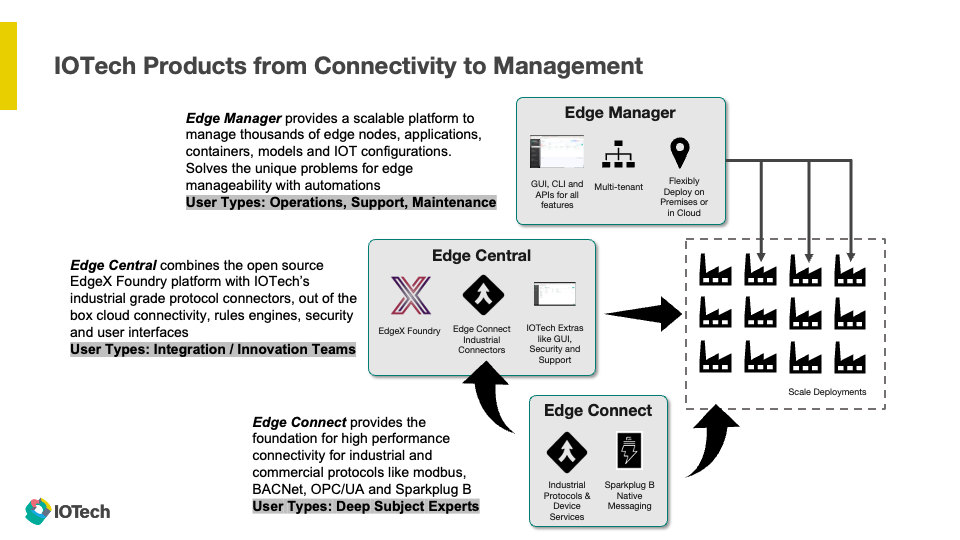
Diagram explaining the relationship between IOTech software solutions
To demonstrate how Edge Central can be applied, I reviewed two customer use cases: Battery Energy Storage Solutions (BESS) and Energy Harvesting. BESS is focused on collecting high volumes of data from the banks and banks of battery cells deployed in grid-scale battery energy projects. Our modbus protocol device services poll at high frequency the status of all the battery cells, as well as other ambient sensors, to create a live and historical record of battery performance. This data can be used to status viewing, or investigating historical performance against stated claims. Data is stored in a database such as InfluxDB or PostgreSQL, and can be exported with queries or Grafana dashboards.
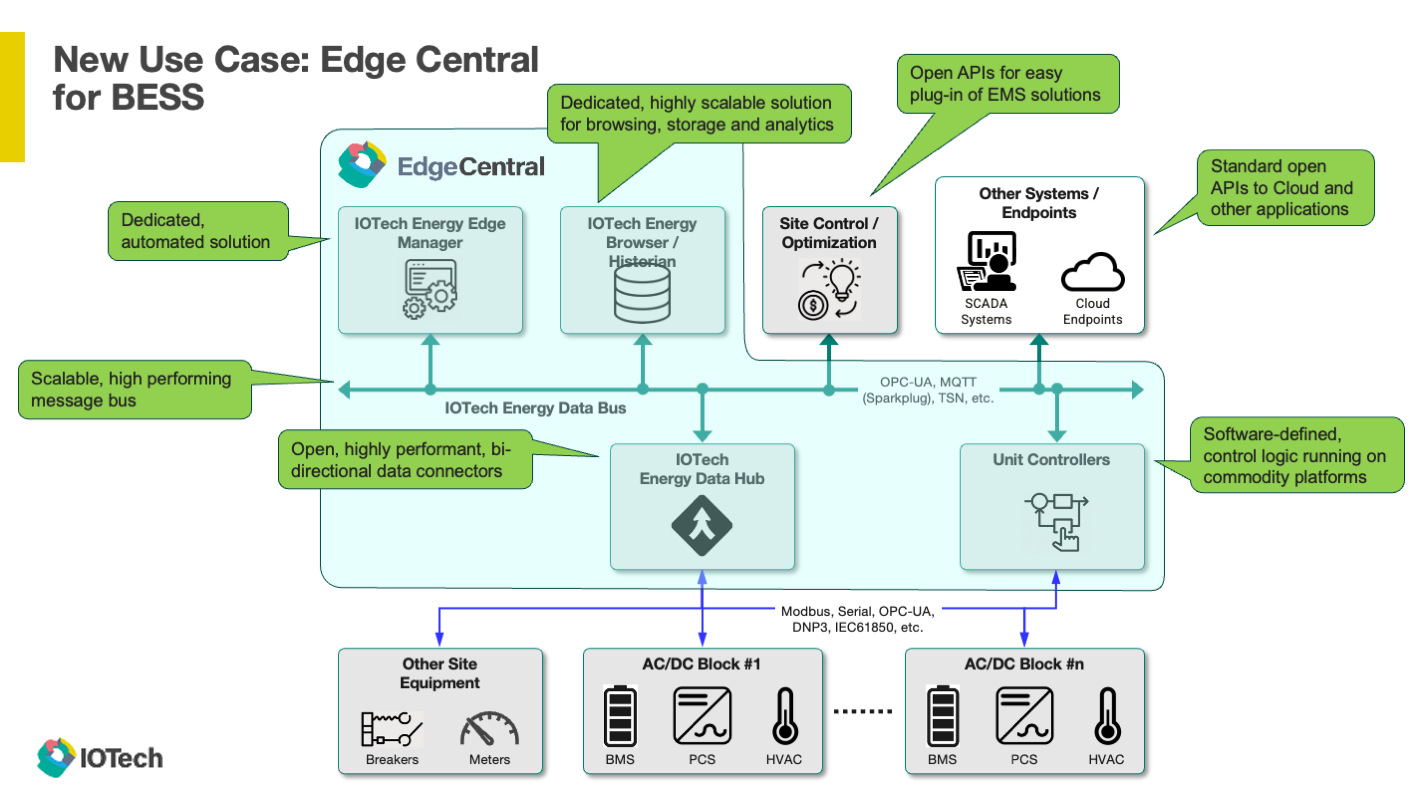
Block diagram for a Battery Energy Storage Solution
The Energy Harvesting use case illustrates how legacy investments can be extended to create new value. Most buildings already have some form of Building Management Software installed, and while Edge Central can play that role directly, many of our customers use Edge Central to extend the types of data collected by the BMS, or increase the data volume for purposes of automating building function for carbon reduction goals. AI models can be trained to optimized energy intensive processes such as chilled water or steam production.
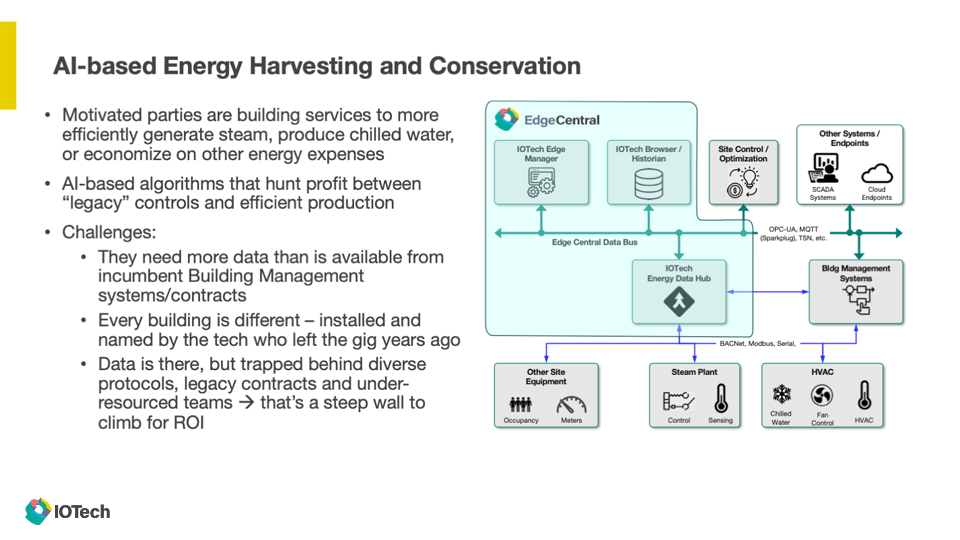
Block diagram illustrating how Edge Central can tap into an existing BMS solution for advanced use cases
The section below summarizes the challenges of moving to Edge Computing, as well as how the solutions from Open Source and IOTech address those needs:
Challenge: Enterprise Compute transitioning to the Cloud, changing technologies and employee skill sets
Resolution: EdgeX, Edge Central and Edge Manager are built with Cloud-native concepts like micro-services, containers and event driven architectures, creating overlapping skillsets for IT teams
Challenge: Cloud-native toolsets are built for dynamic, ever changing workloads, Edge Compute needs uptime and reliability
Resolution: IOTech’s tools utilize Cloud-native tools but with a focus on the same attributes of uptime, reliability – tools that can deliver cutting edge AI/ML technology but operate with the same needs of embedded compute
Challenge: Decades of maturity mean dozens of vendors have locked data behind walled gardens
Resolution: Open and pluggable protocol services allow the mixing and matching of data from protocols across industries
Challenge: Legacy applications have large, inflexible footprints, with dated cloud exporters
Resolution: Edge Central is modular allowing you to deploy only what you need, and composable to create easy paths from data acquisition, to transformation, to cloud export
Challenge: Vendor software is difficult to extend or support
Resolution: Open Source nature of EdgeX along with version controlled APIs means teams can easily extend, integrate or if circumstances require, take over source ownership of the solution
In closing I reiterated that what makes the Edge challenging (and fun) is that it represents a technology transition while also reinventing the need and role of embedded computing, that the Energy sector is well positioned to ride these transformations, and that Acuvate and IOTech are here to support that transition with Acuvate’s Standard Digital Framework.
If this moves you to consider innovating at the Edge, or rethinking your embedded compute infrastructure, please feel free to reach out to me or explore our website: www.iotechsys.com

To dive deeper into the potential of edge technology, together with Acuvate, we are developing an exclusive webinar named the Power of Edge Computing and AI for Faster, Smarter Decisions.
This session will explore how IOTech Edge Central™ enhances real-time data collection and processing with multi-protocol connectivity, while Acuvate’s 7 Steps Standard Digital Framework leverages data streaming, AI analytics, and Digital Twin technology for a comprehensive approach to digital transformation.
Gain insights into how innovations like 5G, AI-driven Machine Vision, AI Machine Learning, and OT standardization are paving the way for the future of Edge Computing. Don’t miss it!
Date: November 21, 2024
Time: 16:00 CET
Platform: Microsoft Teams
Registration link: here